Fabian Karl
Data Scientist
About Me
I'm a 25-year-old Data Scientist and PhD student based in Munich, Germany, with 9 years of programming experience. My journey in technology began in 2016, and since then, I've been passionate about developing innovative solutions using machine learning and artificial intelligence.
Currently, I'm pursuing my PhD at the Technical University of Munich (TUM), focusing on Medical NLP at the Chair of Software Engineering for Business Information Systems (sebis). My research interests include information retrieval, synthetic data generation, and model evaluation. I combine theoretical knowledge with practical implementations to create impactful solutions that bridge the gap between academic research and real-world applications.
Machine Learning
Specializing in neural networks and natural language processing
Research
Publishing peer-reviewed papers in top-tier conferences
Software Development
Building scalable solutions with modern technologies
Innovation
Bridging the gap between research and practical applications
"Our work in AI is as much about solving problems as it is about inventing the tools to solve them. Practical applications drive the necessity for better algorithms."
Academic Journey
Ph.D. Research in Medical NLP at TUM
Moved to the Technical University of Munich (TUM) to continue doctoral research at the Chair of Software Engineering for Business Information Systems (sebis), focusing on Medical NLP with research interests in information retrieval, synthetic data generation, and model evaluation.
Ph.D. Research in Natural Language Processing
Started doctoral research at Ulm University, focusing on advanced Natural Language Processing techniques to enhance machine understanding and generation of human language.
Master's Degree in Computer Science
Graduated with an MSc in Computer Science (Grade: 1.2), with a thesis titled "Retrieval Augmented Information Extraction: Enhancing Language Models for Extracting Bibliographic Metadata from Heterogeneous Web Sources with CRAWLDoc".
Student Research Assistant in Data Science
Contributed to research projects in the fields of Natural Language Processing and language models while pursuing my Master's degree, co-authoring papers on topics like transformer-based models and text classification.
Bachelor's Degree in Computer Science
Completed a Bachelor's degree in Computer Science (Grade: 1.3), with a thesis titled "Transformers are Short Text Classifiers: A Study of Inductive Short Text Classifiers on Benchmarks and Real-world Datasets".
Research Publications
Peer-reviewed publications synchronized with DBLP and manually curated entries
Research Projects
Evaluation of German party manifestos
This project analyzes major German political parties through their manifestos using semi-automatic methods. We applied LDA, HDP, and BERT for topic extraction and categorization, summarizing key themes from each category. An interactive demo allows users to rank these summaries and receive scores for each party, offering insights into their political positions.
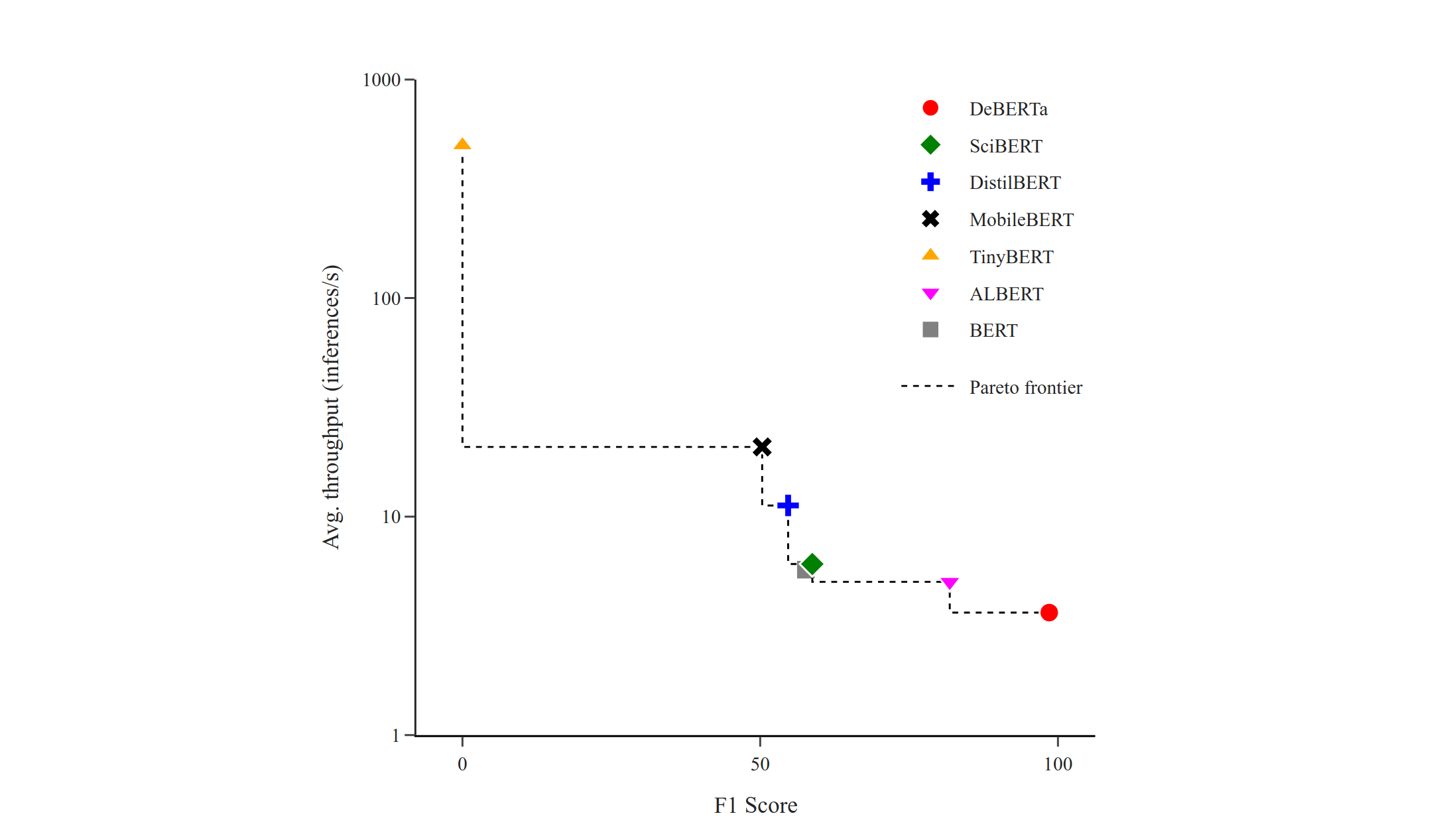
Efficient Inferencing in Language Models for Academic Writing Feedback
This project fine-tunes language models for academic writing, specifically focusing on cite-worthiness detection and section classification. We optimize these models for fast inference using techniques like distillation, pruning, and quantization, evaluating their performance on server CPUs, notebook CPUs, and System on Chip (SoC) devices.
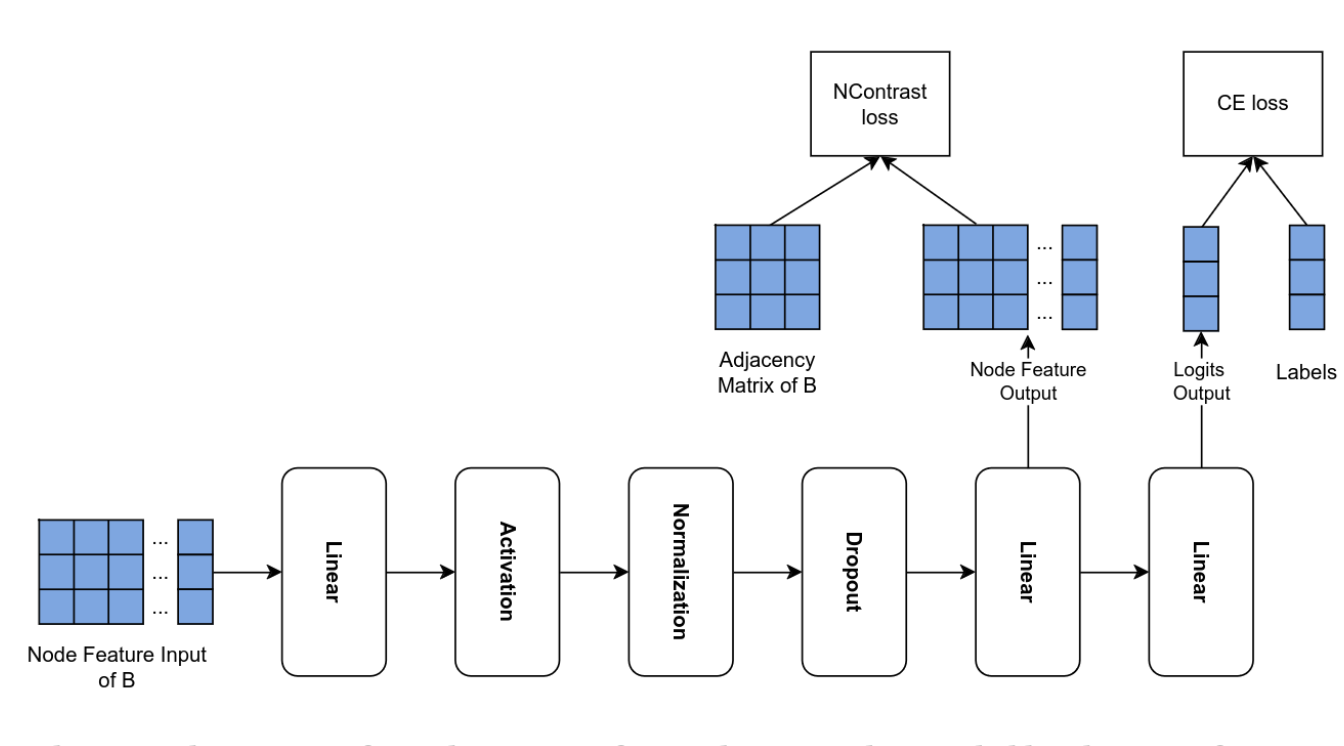
Graph-MLP Sampling
This projects examines the impact of different graph sampling strategies on the performance of GraphMLP. We evaluate thirteen sampling methods across six benchmark datasets, analyzing their accuracy and runtime. Our findings reveal significant variations in performance among the sampling strategies, indicating that no single method is optimal for all datasets. We advocate for treating graph sampling as a hyperparameter that should be tailored to the specific requirements of each task.